I gave a talk recently at RustLab. The talk focused on building with Rust & Serverless; a couple of slides related to this serverless spectrum triggered some discussion afterwards. This post is me pulling together some of these ideas and trying to make sense of them.
Serverless Is A Spectrum, Not A Binary Decision
The limitations of Markdown don’t allow me to make that point any more strongly. When you choose the compute to run your application, you have a wide range of options, from bare metal instances running in a data centre to serverless functions and many steps in between.
Boxing yourself into ‘serverless only’ or ‘Kubernetes only’ limits your options. Every organisation I’ve worked in has some use cases that better suit a long-running container and some use cases that suit a reactive style of computing.
Of course, it’s possible to run long-running web apps on serverless functions and reactive compute on Kubernetes with services like KEDA. But is that what we want? Aren’t we just forcing square pegs into round holes?
My mental model for compute is thinking about it as a spectrum. Where you choose to sit on that spectrum will depend entirely on what your application needs.

A spectrum is a much more interesting model for thinking about compute choices. Look at your application and its requirements, and then decide what is most important.
Imagine for a moment that you’re building an app with an interface that serves web requests. Those web requests are persisted and sent off for background processing.
Now, imagine that the background process needs to run a complex algorithm that would benefit from having access to a GPU. For that kind of system, you need infrastructure flexibility.
Your application needs a specific piece of infrastructure to function, so you need to take on the additional operational responsibility of running that infrastructure.
The web component, on the other hand, is just a simple web interface that receives requests and passes them on. It’s largely irrelevant how that component runs; you just want it to be reliable and available.
Different components of the same system have different requirements. Let’s make this more tangible for a moment.
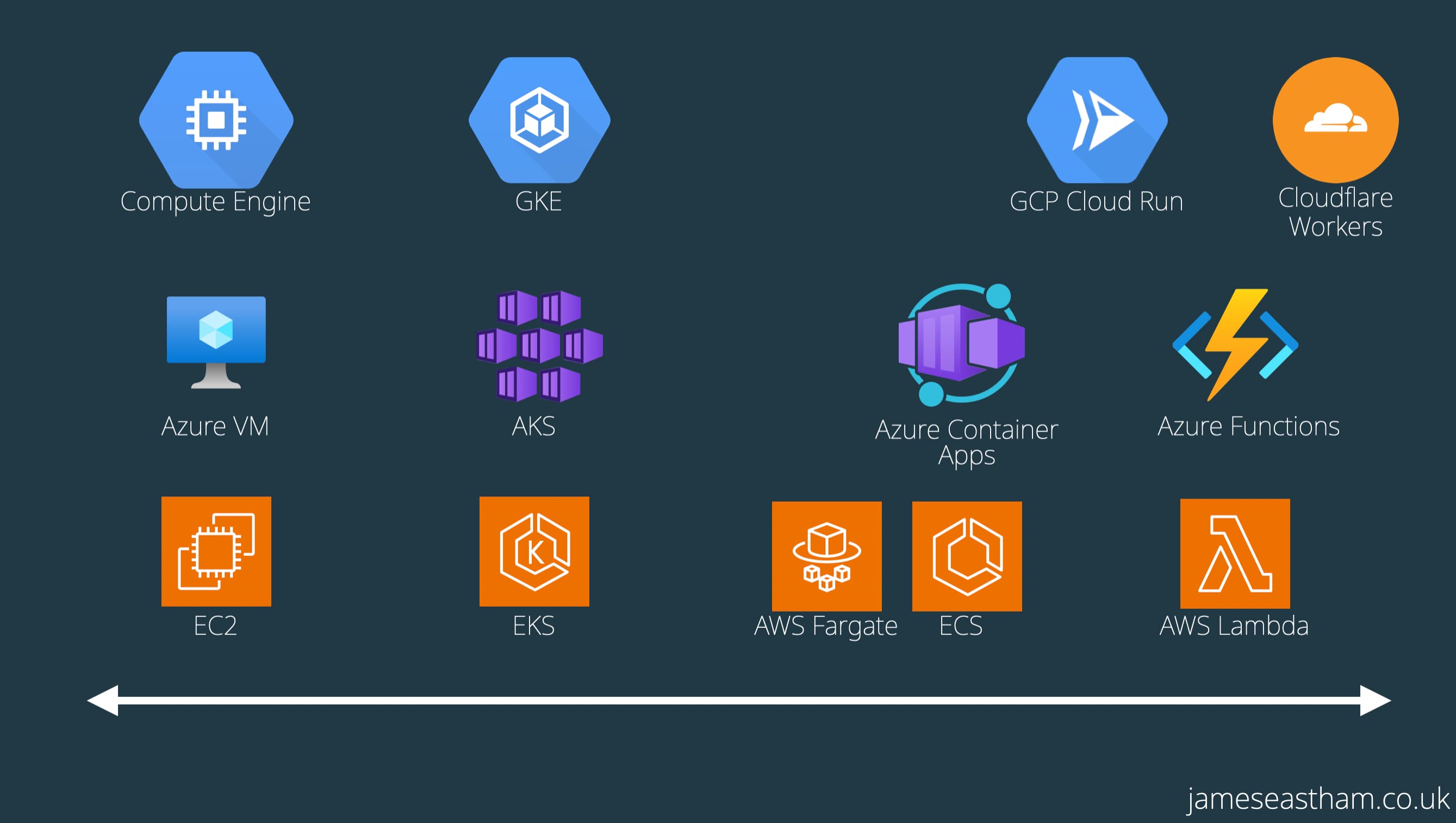
That’s the range of compute options you have across the cloud providers. Of course, running your own machine in a data centre also sits off the far left of that spectrum as well.
The web component of your application could sit anywhere. My argument would be to run that as far right as possible.
Your users don’t care about the compute it runs on, your users just want the app to work
The component that requires specific compute, though, clearly needs to be further left. You need control over the infrastructure. How far left, of course, depends. Which brings us onto the second dimension of compute decisions: cost.
This cost slide generated the conversation, and it was actually a last-minute addition to the talk.
The keynote from the previous evening at RustLab was an interesting real-world use case. The speaker briefly mentioned their choice of compute. They were running their Rust application on Kubernetes, and the reasoning was, “Lambda, ECS are more expensive.” I’m paraphrasing there, of course.
My issue with that is that it reduces the cost of a system to the dollar value that AWS invoices you at the end of the month. That’s oversimplifying it.
There’s a reason serverless services have a higher line item cost: You’re paying someone, somewhere, to run your infrastructure. The cloud provider is your platform team.
Running virtual machines and operating Kubernetes clusters have costs beyond the line item cost that a cloud provider charges. As Werner Vogels so perfectly described in the frugal architect cost and sustainability are important considerations for building modern systems. I don’t know Werner personally, but I’m pretty sure he isn’t just referring to the line item cost on your AWS bill.
That isn’t me shitting on Kubernetes; it has a place in the world. But the vast majority of systems don’t need Kubernetes.
Back when I worked at AWS, there was an interesting heuristic that I heard internally. Which was
Kubernetes is useful if your ability to scale infrastructure dynamically is a differentiator for you business
Going back to the app you’re building, the algorithm component has specific infrastructure requirements, and that infrastructure needs to dynamically scale up and down based on load. It feels like a good fit for Kubernetes.
Does that necessarily mean your entire organisation needs to adopt Kubernetes? I’m not so sure. Could the web component run somewhere with lower operational overhead? Something like Lambda? somewhere where you can deploy the app and not worry about it until you need to make a change to it. Definitely.
The counterargument is that once you’ve put time and effort into building a container platform, surely you might as well mandate that all teams use it.
It’s a convincing argument. It’s a good argument. One I’m not sure I have a good argument against.
My only critique of that approach is that it has introduced a single point of failure and a bottleneck into your system.
The single point of failure is the cluster itself. You’re now running multiple (potentially critical systems) on top of a piece of infrastructure that relies on a single team (the platform team) patching and upgrading it every 6 months and in a way that ensures reliability.
That’s entirely possible, of course. But it feels like we are returning to a world where Dev & Ops are split.
One of the core principles of DevOps is “you build it, you run it.” Now, you build it, and someone else (a platform team) runs it. You might be on-call, and you might build observability and alerts. But fundamentally, someone else is running the underlying infrastructure.
This brings me back to the idea of a compute spectrum. In my opinion, a good architect provides guardrails, not mandates.
A guardrail could be your service has to communicate over well-defined APIs.
A guardrail could be that your applications must be packaged as containers and be stateless.
Empower teams to make decisions that suit the specifics of their workloads. Because, at the end of the day, those teams know their workloads the best.